Kafka
NTTデータは、高い専門性と多くの実績による知見に基づき
システム全体で最適な構成でデータメッセージングを実現します
FEATURES
Kafkaの特長
①サーバの追加による性能向上(スケールアウト)
- Kafkaは構成するサーバの台数を調整することで全体の性能を調整できる構造になっており、サーバの台数を増やすことで、性能の向上が行えます。Kafkaのサーバの追加は運用開始後でも行うことができ、一定の制約はありますが、サービスを停止させずに行うことも可能です。小規模の運用から開始し、取り扱うデータ量の増加に伴ってサーバ数も増やしていく、いわゆるスモールスタートでの利用も可能です。
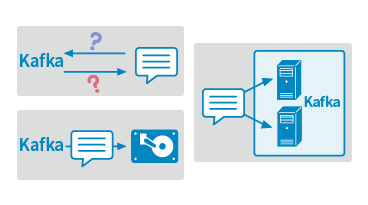
②ストリームデータの確実な取り扱いのための機能
- ストリームデータは連続的にデータが流れるという性質上データを失うなどのリスクが高く、データを確実な取り扱うために考慮しなければならない点が数多くあります。Kafkaにはメッセージの送達保障、レプリケーション、データのディスクへの保存などストリームデータを確実に取り扱うための機能が標準で備わっています。これらの機能を活用することで、商用で利用するようなシステムであっても比較的容易にシステムの設計などを行えるようになります。
③多くのストリーム処理エンジンやツールがKafkaに対応
- Kafkaのようなメッセージングシステムは通常単体で利用されることは少なく、データの処理を行う処理エンジンやデータの転送を行うデータローダなどと組み合わせて利用されることが多いです。KafkaはSparkなどの処理エンジンやFluentd(※1)などのデータローダなど数多くのプロダクトと連携して利用できるため、実現したい処理に合わせて利用プロダクトを選択できます。

SOLUTION
NTTデータのKafkaソリューション
サービスの概要
NTTデータのサービスと一体で、または単独のサービスとしてデータの活用/処理の企画段階から運用段階までをトータルに支援します。
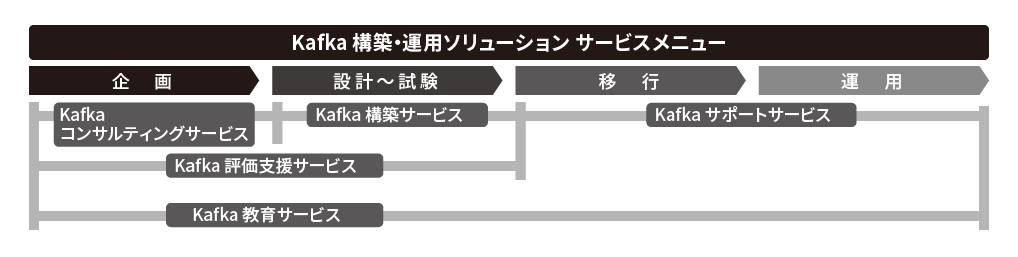
| Kafka コンサルティングサービス |
お客様が保有する多種多様なデータの活用し、新たな価値を生み出すために、専門技術者がご支援いたします。 提案支援、システム化コンサルティング、設計書レビューなど、まずはご相談ください。 |
|---|---|
| Kafka評価支援サービス |
実機を用いてKafkaを評価したいというお客様を、専門技術者がご支援いたします。 検証方法のご提案~結果の分析、チューニング観点のアドバイスなどを行います。 |
| Kafka構築サービス |
十数~数千台の構築経験を活かして、専門技術者がKafkaシステムの構築を実施します。 最適な機器選びからチューニングまで、トータルにご支援いたします。 |
| Kafkaサポートサービス |
Kafkaの保守契約です。基本サポート内容はメールベースの技術問い合わせ・故障問い合わせ対応です。
保守プロダクトは、Hadoop、Spark、Kafkaをはじめとするオープンソースソフトウェアです。 オプションとしてオンサイトの故障対応も実施します。ご希望の方はお問い合わせください。 |
| Kafka教育サービス | 「社内にKafka技術者を育成したい」等、プライベートセミナをご希望の方はお問い合わせください。 |
NTTデータならではの強み
-
データ活用基盤全体のコンサルティング・インテグレーションに対応
データ活用の基盤の多くは単一のプロダクトの利用ではなく、複数のプロダクトを適材適所で併用して構築されます。NTTデータのKafkaソリューションでは、Kafkaに関連する設計・構築・運用のご支援はもちろんのこと、HadoopやSparkなどほかの大規模データを扱う基盤との連携も考慮し、システム全体で最適な構成となるようコーディネートすることが可能です。
-
専門技術者による技術支援
コンサルティング・構築支援・サポートサービスの各技術支援は、ソースコードレベルでの問題解析が可能な高度な専門性を有する技術者が対応します。
-
業種・業態を問わない幅広い実績
NTTデータのKafkaソリューションはすでに幅広い業界・業務のお客様にご利用いただいています。対応技術者の高い専門性と多くの実績による知見に基づいて、お客様のデータ活用をご支援いたします。
USE CASE
Kafka ユースケース
リアルタイムにデータを扱う(収集・連携・処理)する際に利用されます
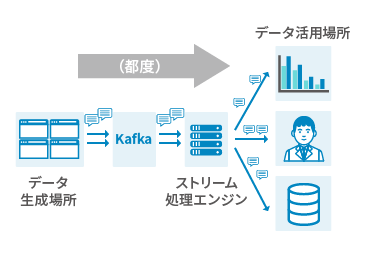
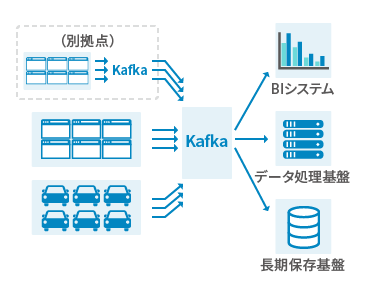
ケース1:大量のデータのリアルタイムの収集・連携
都度生成/送信されるストリームデータを一度Kafkaで受信し、データ処理基盤やデータ分析基盤などデータを活用するシステムに必要なタイミングで連携します。
-
Kafkaを利用するメリット
- 高い拡張性 (将来のデータ量・接続システムの増加に対応)
- 複数のシステム間の連携が容易 (N:Mでデータでの収集・連携が可能)
- 連携のシステム間の影響を最小限にできる (システム間が疎結合に)
ケース2:大量のデータの逐次処理(ストリーム処理)
ストリーム処理エンジンとKafkaを連携し、Kafkaで受信したストリームデータを順次処理(ストリーム処理)することで、バッチ処理では実現できない短時間での結果の出力を実現します。
-
Kafkaを利用するメリット
- 高い拡張性 (将来のデータ量・接続システムの増加に対応)
- データ欠損のない確実な処理の実現(送達保障などのKafkaの機能を利用)
- 連携のシステム間の影響を最小限にできる (システム間が疎結合になる)