Spark
ABOUT
Apache Sparkとは
Sparkで実現!「機械学習」「分析や試行錯誤」「業務データ処理」「データ加工」「ストリーム処理」
10年を超えるHadoop等並列分散処理システムの設計・構築・運用実績で培った知見や実装レベルの知識を活かし、Sparkを効果的に活用したデータ活用基盤を実現します。 大量データの高速な処理から、機械学習等の分析業務への適用まで、コンサルティング・ PoC・システム構築・運用設計・導入後のサポートを幅広く提供いたします。
FEATURES
Apache Sparkの特長
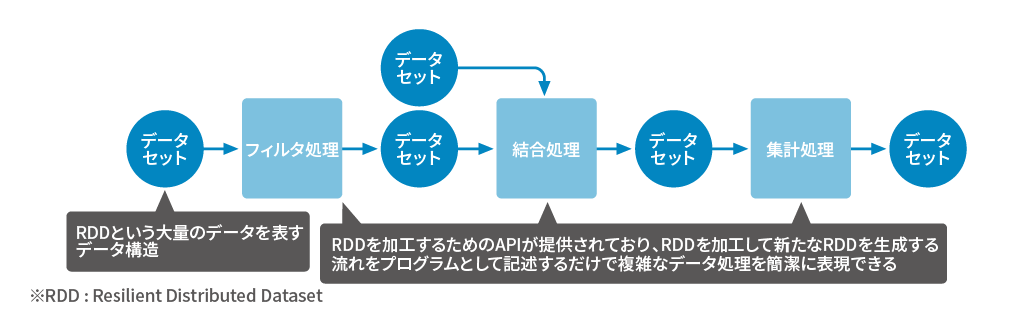
Sparkは大量データに対し高速な並列分散処理を実現します。Sparkはデータソースからデータを読みだしたあと、ストレージやネットワークのI/Oが極力少なくなるように処理します。このため、Sparkは同じデータに対する変換処理が連続するケースや、機械学習における学習処理のように複数回繰り返し処理を行う処理にも適します。また、Sparkの高速な処理機構を活かしストリーム処理を行うこともできます。